
懂不懂我们,啊,U+202E 的含金量啊。
由于工作上的需要,开发了一个用于文字排版的算法。
说是文字排版,其实就是把已知需要支持的语言的字符一个个放到屏幕上。这听起来是一件很简单的事情,但是实际上并非如此。我前前后后花了那么一段时间(大概一周)来编写和调试这么一个算法,但它到现在也只能处理一些简单的情况。
只能说,把所有人类文字都正确地显示在电子屏幕上,本身就是一件奇迹了!
翻译控制
本文使用由 FontForge 提供的术语翻译作为共识性翻译。
Unicode 和 UTF-8
我们现在的工作,也是站在巨人的肩膀上进行的。统一码联盟 (Unicode Consortium) 经过几十年的努力收集并统一了人类语言文字在计算机中的表示,所以我们现在就不再需要去处理更为棘手的编码判断和内码转换了——我们只需要统一使用 Unicode 进行字符编码,并使用 UTF-8 作为信道编码即可。
然后我们首先遇到的问题,就是处理非法输入。具体的,一段字节流可能并不符合 UTF-8 标准,此时的你,应该怎么做?
0xe6 0xb5 0xe8 0xaf 0x95 0x41 0x41
第三个字节是缺失的,它反而是下一个位点的开始。这时候,前两个字节应该单独产生两个问号呢,还是只产生一个问号呢?换个问题,如果当前字节是无效字节,那么你应该尝试从下一个字节继续解码,还是从下一个有效边界开始继续解码呢?
我选择了后者——我认为这是一个更合理的方案。
怎么把字符画到屏幕上
我并不,也不应该操心平台如何具体地获取字符数据、栅格化和写屏幕显存。但我关心的是:我会一行行地按一定像素宽度排布文字,每行的高度恒定不变,但我并不关心当前是第几行。所以我们定义两个原语:get_glyph_metrics 用于获取某个位点的字符度量信息;draw_glyph 将某个位点绘制到给定的左偏移量上。
字符度量信息 (Glyph Metrics)
对于非定宽字体来说,字符度量信息包括图 1 所示的内容:
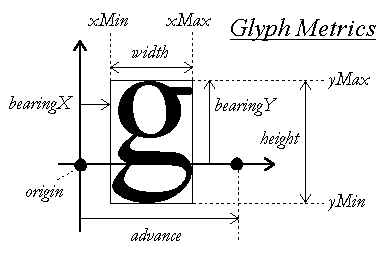
有趣的是,字符的宽度 (width) 和步进宽度 (advance) 是不一样的。下文为了行文简便,「宽度」特指一个字符的步进宽度。
从左到右的非定宽文字排布
首先,我们来考虑比较简单的情况吧:从左到右的非定宽文字排布。这绝对不是为了给后面的恐怖情况埋伏笔。
这个从思路上来说非常简单:挨个获取字符宽度,如果放得下的话就把字放上去就可以了。

以给定符号结尾
如果能够显示整个字符串,那么显示整个字符串。如果不能,则结尾显示一个省略号。
这是相当常见的要求。当然,这样做会稍微有些复杂,因为需要考虑「能不能显示得完」。我们同时会希望使用尽可能少的原语——因为这些原语可能是非常耗时的(相比起我们做内存内的计算,原语给定的操作可能需要读取外部存储器,这是相对而言非常慢的操作)。
那么,我们可以假定我们需要显示这个省略号,一开始就预留好它的宽度;之后排布文字时,如果即将超过预留宽度,那么判断是否到最后一个待排布字符;如果是,则尝试进行排布,放不下或者不是最后一个字符则直接排布省略号。为了通用性,这个省略号的位点可以自行给出——或者留空表示此处不需要省略号,比如多行排布的情况下,除非遇到最后一行,否则不需要在末尾添加省略号。

从右到左的非定宽文字排布
从右到左无非是从左到右的镜像——如果能塞下,就塞;塞不下就结束。不过判断条件从右边界超过宽度变成了左边界为负值。

同样的,也需要考虑省略号。算法总体和从左向右排布类似。
符号镜像
但是从右向左的文字在使用成对标点的时候,仍然使用原来的位点。比如小括号,无论是拉丁文还是希伯来文,都使用 U+2e 作为开头括号,而它们两个的显示是刚好相反的。如图 5 所示,颜色一致的括号有相同的位点,但展示时,希伯来文的红色括号开口向左;拉丁文的红色括号则向右。

一个非常直白的方法是:如果我们需要绘制镜像的字符,那么我们就真的去找镜像的字符并绘制。好在需要进行镜像操作的符号并不多,主要是三个括号和问号。其他语言的括号,比如中文括号,姑且认为是具有强方向性的,所以并不进行镜像。
多方向的文字混排
然后,就是重头戏了:如果一段文字里,既有从左向右的文字,又有从右向左的文字呢?
Unicode 双向文字排版算法
统一码联盟实际上已经给出了我们完整的双向文字排版算法了,我们只是需要实现它而已。
但是这份文档对于大多数而言几乎就是一年的英语阅读量;想要啃完这份文献、理解并完整实现这部分内容本身就是一件相当刺激的事情。所以我们就一点一点根据自己的理解来尝试实现一个子集好了。
文字的方向属性
一个字符的方向可以是「向右」、「向左」或者「中立」。大部分的语言文字是向右方向的;而阿拉伯文(含波斯语扩展)、希伯来文(含意第绪语扩展)则是向左方向的。(向左方向的文字系统还有很多,但由于我的工作中接触不到所以按下不表。)
特殊的,所有的控制字符、白字符、不属于特定语言的标点符号是方向中立的。我们之后会需要考虑这样的内容。
文字区段
同一个方向的文字形成一个文字区段。而文字区段的匹配是贪婪的:如果匹配时遇到了中立的字符,那么继续向后搜寻,直到遇到结尾或者一个有强方向的字符;如果遇到的字符和当前匹配字符的方向一样,那么中间的中立字符也视作相同方向的字符;如果遇到了结尾或者不同方向的字符,则中立字符单独成为一段。
如果中立字符是表现有方向的(比如括号),那么也需要按照方向做镜像。但是有一个特殊例外:阿拉伯文括号不做镜像。
全局方向
一段文字有主体语言,而这主体语言将会决定这段文字是总体从左向右排列还是从右向左排列。由于这套算法需要运行在嵌入式设备上,所以我并没有扫描整段文字的奢侈,故选择按照系统语言决定全局方向:如果系统语言是从左向右的,那么默认方向就是从左向右;如果系统语言是从右向左的,那么默认方向就是从右向左。
简单的混排算法
当我们完成文字区段的划分之后,我们就可以按段来排布文字了。对于和全局方向一致的内容,可以简单地使用之前确定的排布算法;对于和全局方向不一致的内容,则首先尝试测量能否放下整段文字,如果可以放下,则按当前使用的排布算法倒序排布每一个位点;如果不能放下,则查找尽可能长的子区段,并将子区段放入。如果有需要,则按最后一次排版的区段放置末尾截断符号。
阿拉伯文
上述排版算法没有考虑到一个非常关键的东西:阿拉伯文。
阿拉伯文有一个非常有趣的特性:除非彻底没有备选方案,你不能在词的中间换行。之前我们的算法只考虑了拉丁文和希伯来文,而这两种基于字母表的语言都是允许在词中间进行换行的——当然,可能会需要插入连字符之类的。
这个时候,我们的算法就必须先进行搜索,如果当前从右向左的文字区段中包含阿拉伯文,那么则需要倒序搜索能放下多少个词并放下尽可能多个。如果一个词都放不下,那么则需要将单词从中间打断,同时将被打断的地方改写为独立形式。
合字规则
合字规则即当一些位点相邻(或者不相邻)时,这些位点的显示形式需要被转换为另一种形式。一个典型的合字是 fi/fl 合字,如图 6 所示:
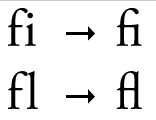
一个比较简单的方法是通过预先读取若干字符,如果搜索到了这些对应的字符,则生成对应的表现形式。
阿拉伯文变体规则
阿拉伯文在编码时,通过 ISO-8859-6 进行;但是其展示形式则有一个非常复杂的定义。
阿拉伯文有一个非常有趣的书写系统:其字符会在词头、词中、词尾产生不同的变化,如图 7 所示:
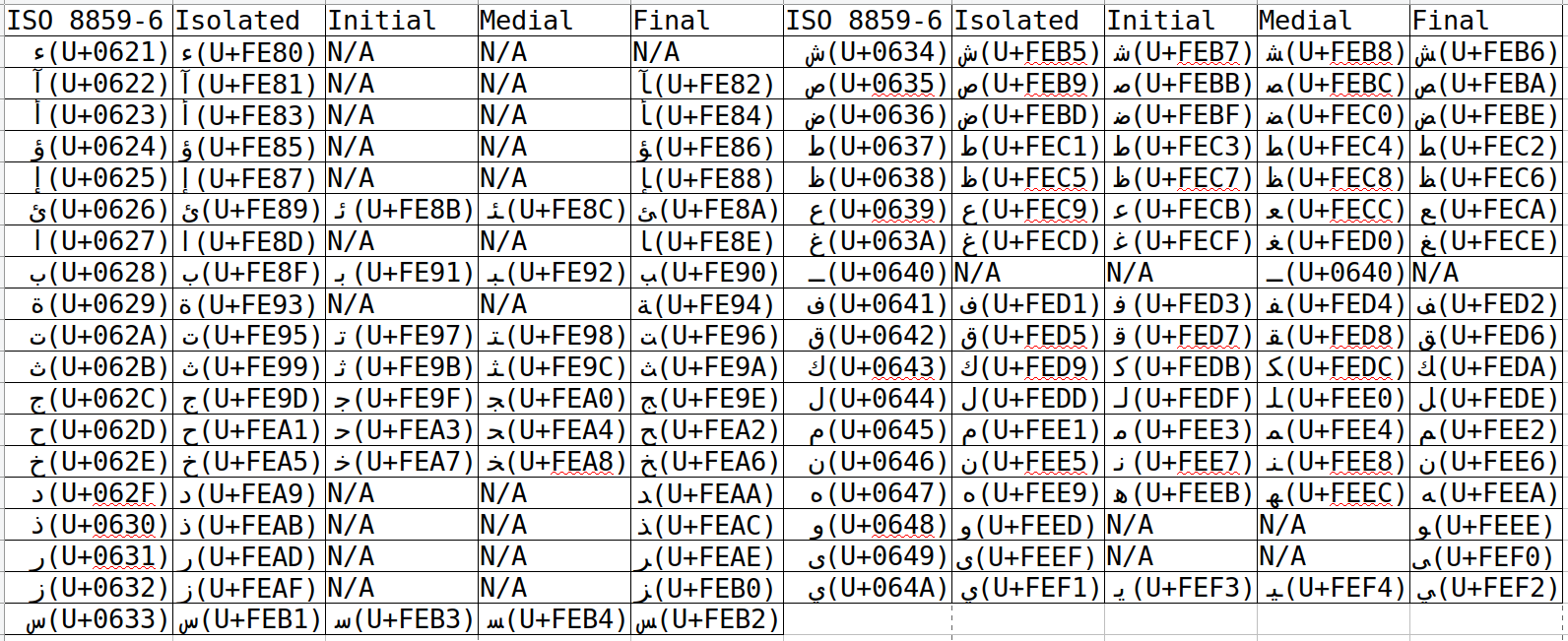
对于我们而言,其实也不是很复杂:幸好阿拉伯语是使用空格 (U+0020) 分隔每个单词的,所以判断字在词中的位置还是相对容易的。对于那些更恐怖的书写系统,我们暂时不做太多考虑——它们本身就可以单独成一篇文章了。
Unicode 等价性
谈到合字,就不得不谈一下 Unicode 等价性。
由于 Unicode 的通用性,导致有许多看起来相同的字符有不同的编码方案。考虑 é, 它实际上有两个编码方案:U+0065 U+0301 (字母 e 和符号 ◌́)和 U+00e9 (有上撇号的字符 é)。对于更复杂的文字系统,则可能会有更复杂的组合 - 拆分形式。
取决于设备上的字库实现,我们可能需要更偏好于拆分形式或者更偏好于组合形式;或者视情况选择对应的值。甚至,我们可能还需要考虑那些看起来一模一样但是分配了不同位点的字符(比如拉丁字母 o 和希腊字母 o),是否要根据设备字库进行对应的偏好性选择。
Unicode 控制字符
Unicode 里还包括了一些不可见的「字符」,但是这些字符是会影响文字的排版行为的,所以我们要么选择过滤掉这些位点不处理;要么就需要按照 Unicode 的意思做一些操作。
我们在这里暂且只关心文字方向控制有关的内容。至于 Emoji 那一块,由于大部分 Emoji 不在基本多语言平面上,所以我们就不去管了。
零宽有向字符
Unicode 定义了三个零宽有向字符(左向右零宽空格、右向左零宽空格、阿拉伯数字空格),当进行区段解析时,它们可以用于指示中立文字的方向而不需要额外的字符渲染操作。
强制指定文字方向
Unicode 还额外定义了两个强制文字方向指定字符(强制从左向右、强制从右向左)。当遇到这些字符时,从该字符起到下一个强制指定方向或者清除标记止,无视文字固有的方向,按照该符号指定的方向进行排布操作。
美观处理
从这一部分开始,就是为了美观而做出的一些改善了。毕竟下了这么大功夫来做文字混排这件事情,不如就做好。我想把这部分内容变成我愿意署名的作品,而不是应付差事而潦草写下的代码。
避免在不应断行的位置断行
首先需要考虑的就是一些断行情况实际上是不允许的。
避免一行以符号开始
逗号、句号等标点符号不能作为一行的开头,这意味着换行不能出现在这个符号之前。
处理这样的情况一般比较简单,即在即将插入断行时,验证下一个字符是否属于不得作为行开头的符号。如果是,则提前一个字符插入断行;如果提前一个字符刚好落在不可换行的位置(比如是阿拉伯文单词),则不断向前查找直到可以断行的位置。如果这个可以断行的位置是行首,那么则放弃这个规则。
避免配对标点的起始形式出现在一行的结尾
但有些时候我们希望尽早插入断行,比如起始引号不能作为一行的结尾。
如果当前文字是不可出现在一行结尾的字符,而剩余可排版宽度不够导致即将插入一个断行,则除非该字符是该行唯一存在的字符,则立即插入断行使得当前字符在新的一行开始。
避免以白字符作为一行开头
如果换行之后刚好是个空格,那么下一行的开头就会莫名有一片空白。这是不允许的。所以我们需要额外控制当开始排版时,如果当前位置是白字符,则跳过该字符。
两端对齐
到这一步就是纯粹闲得慌了。由于在嵌入式设备上这样做根本不合理,所以接下来的部分只是一些想法而不是我已经确切实现的内容。
换行的位置可能比较早,这样的话一行的尾部就有一段空白。如果可能的话,此时应该将本行的字符尽可能的向两侧拉伸。一个简单的方案是在各个字形之间尽可能均匀地插入空白。
不过,稍微讲究一点的同学们可能会意识到,均匀地插入空格可能还是会产生很难看的结果。我们应该考虑做更细致的字句调整 (Kerning) 操作,如图 8 所示:

字距调整和合字规则一样,不过不需要表现形式的转换,而仅需要对坐标进行一些调整。但字距调整可能需要按字体进行,而不是和合字规则一样有固定参考;不过字体文件内一般会对默认字距调整有指定,可以进行参考。
相对于英语,其实汉语简单多了,英语里乱起八糟的规则太多。