
答:不要想。
本文章讨论的是 OpenMV, 一个用于实现嵌入式计算机视觉的集成开发板;请不要与 OpenCV, 一个开源的计算机视觉框架混淆。
你可以在这里下载完整的 OpenMV Python 代码。
目标
在一张白纸上,以 Times New Romans 字体打印的尽量大的 A 至 F 共 6 个字母,每个字母单独在 1 张 A4 纸上。要求飞行器正确识别这些字形,并降落在给定字形上。飞行开始前,可以手动设定字符,飞行过程中,除非手动中止任务,不得手动控制飞行器。
对于我的问题就是:怎么正确地识别字形。飞行器的控制由队友搞定。
方案
我们的硬件选择也十分有限,竞赛明确要求不得使用树莓派等高算力系统,所以尝试搞个树莓派跑字符识别是不可能的。我们有的东西很简单:OpenMV. 我的任务就是想办法用这个小东西识别字符。
首先,介绍一点背景:OpenMV 是一个集成计算机视觉硬件方案,以 MicroPython 作为编程方案,带一个 SD 卡接口用于存储脚本和拍摄图像。但是它有一个弱点,就是算力不够。手册上明确指明:不要尝试在这个东西上做光学字符识别,搞不定的。当然,算力低并不一定是个问题,有些时候我们可能高估了任务所需要的算力。
神经网络
提到字符识别,现在很难不想到神经网络。毕竟三层卷积网络就能识别手写数字,那我按相同的思路训练网络识别字母不是很简单的事情?
但实际上,不行。OpenMV 倒不是不支持神经网络,事实上它完全支持,甚至最近添加了 Tensorflow Lite 模型的支持。但有一个问题:我从来没有接触过如何训练 Tensorflow 网络,而且训练模型这个任务似乎在一台 Thinkpad T410 上完成有些过分了。我们也没有合适的数据集来确保网络的输入一定正确。而且,如果我们复用现有的字符识别网络,它也会太大——340KiB, 而我们手头上只有 OpenMV M7 可用,它的堆大小只有不到 80KiB. 如果我没记错的话,模型是不可以裁减的,对吧?
还有一个方案是训练 LeNet. OpenMV 也支持加载一个 LeNet 模型,但我们也面临着上述的问题:没玩过,以及没有现成的网络,以及成果可能太大装不下。
特征匹配
OpenMV 支持创建图像的特征,并进行特征匹配。特征创建比起神经网络而言还是一个非常简单的过程的——导入一张图片,得到一个神秘特征值。把这个神秘特征值加载进来,就可以对图像进行特征匹配了。
但特征匹配面临两个问题:一是特征太少的情况下,不能很好地识别字符,轻微的旋转都有可能无法匹配已经创建的特征;二是如果加载太多的特征,整个算法的运行效率会非常非常低,低到讨论「帧率」已经没有意义,而应该讨论「帧周期」。
那么,显然我们需要用——
野路子
说是野路子,其实更像是非常原始的计算机视觉,即手动计算机视觉。人工智能嘛,有多少人工就有多少智能!
字符集非常有限,加上连字体都设定好了,那不如一把给个过拟合的模型,就只会识别这些字符。
实现
OpenMV 还是提供了不少原语辅助我们实现野路子方案的。这些原语包括:
- 获取像素
- 查找色块
- 查找矩形
- 自动曝光
好,那么开始吧!
黑白灰
由于颜色在这个任务中并不必要,所以我们没有必要采集颜色。只使用灰度模式就可以了。使用灰度采集也有助于提升系统性能。我们的分辨率也不需要很高,使用长焦镜头配合 QQVGA 足以凑合。
但是这同时带给我们第一个问题:色块查找是通过阈(yu4)值实现的,而阈值的具体值是受环境光照影响的。尽管有自动曝光功能,但实际上这只是为了传感器能够获得清晰的图像。
其实这里也需要简单地讨论一下人眼对颜色的感知。人眼对颜色的感知并不是绝对的,而是根据环境自动调整和补偿的。比如,荧光灯的光偏蓝、卤素灯的光偏黄,但是在这两种光照条件下,同一个物体的颜色看起来大致相同,这是因为你在意识里减去了环境光本身的颜色。

这张图片是颜色自动校正的绝佳样例。你可能会看到香蕉是黄色的、杯子是灰色的、杯子上方植物的叶子是绿色的、手是肉色的。但实际上,使用照片编辑器查看各个像素,你会发现这只是不同饱和度的红色——整张图片只有不同饱和度的红色,而没有其他颜色。
现在,我们需要教会机器产生这种「颜色错觉」,让它更贴近人眼看到的情况,再做进一步处理。
我们目标场景内可以确切知道颜色的东西有两种——白纸和黑字。而我们寻找黑字的过程是需要调整阈值的,但是寻找白纸的过程不需要,因为矩形查找是通过边缘查找完成的,而边缘查找只对对比度敏感。
你可能会问:那为什么不干脆直接用边缘查找的方法识别字符呢?答案是:这又回到神经网络去了。边缘识别算法固然稳定,但是要手动处理边缘需要更聪明的方案(比如二维傅立叶变换),以及竞赛的时间不容许我慢慢读关于指纹识别的论文并从中汲取灵感。
所以,校准白色的方式就得到了:首先,查找画面中的矩形(应该只有一个),然后取矩形内部 10 像素的像素点,作为标准白色。
取到标准白色点之后需要对图像做处理,使得标准白色的值成为 0xff. 这需要用到图像的卷积操作。
图像卷积
图像的卷积操作围绕着一个卷积核进行。卷积核通常是一个大于 1 的奇数阶方阵,在这里我们使用 3 阶方阵对图像进行处理。
首先,我们希望对图像的对比度进行处理,使得标定白色成为 0xff. 这个可以通过单位卷积核乘一个系数完成。系数的值即为 0xff 与该像素的灰度值之比:
\(\mathbf{K}_{contrast} = \begin{bmatrix} 0 & 0 & 0 \\ 0 & k & 0 \\ 0 & 0 & 0 \end{bmatrix}\)
我们也可以选择使用锐化卷积核使得字体轮廓更为清晰一些:
\(\mathbf{K}_{sharpen} = \begin{bmatrix} 0 & -k & 0 \\ -k & 5k & -k \\ 0 & -k & 0 \end{bmatrix}\)
二值化
完成卷积后,二值化过程很简单——设置一个阈值,凡是低于这个阈值的视作黑色,高于这个阈值的视作白色。但我们没必要对整个图像进行二值化,我们只需要对关心的位置进行二值化。
一维模式
我们仍然需要从图像中提取模式。一个符合直觉的模式提取方式即一维模式提取:沿着一条线,提取一个黑白模式。而且为了简单起见,我们只提取颜色而不提取颜色的长度。这代表只要有一个像素与之前不同,就产生一个反转位。

在上图中,红色为检测线,产生的模式即为 0101010101. 尽管黑白条的长度并不统一。
检测点
检测点则是更简单的模式:某个像素点的颜色是黑色还是白色。
检测线
检测线则是稍微复杂的模式:沿着这条线,如果有任何一个像素点是黑色,那么检测结果就是黑色;否则为白色。
像素距离
虽然我们并不打算在一维模式中计算颜色的长度,但是我们仍然可以编写计算像素距离的函数。在这里我们关心的是从一个白色像素点出发向一个固定方向,与之最近的黑色像素的距离。
逻辑总成
在有了上述检测功能后,我们就可以开始做逻辑总成了。
由于指定了字体,我们可以有的放矢。首先,用查找色块功能框选出对应的字母的色块:

在框内设定相对坐标系:令框的左上角为 (0, 0), 框的右上角为 (1, 0), 框的左下角为 (0, 1).
从 (0.5, 0) 划线到 (0.5, 1); (0, 0.5) 划另一条线到 (1, 0.5) 进行一维模式检测:

感觉上我们似乎可以单纯地使用这两个一维模式就搞定检测,不过实际上许多字母的一维模式采样结果是一致的。而且随着镜头略微的旋转,产生的模式也会跟着出现显著的变化。要减轻这种变化的一种方案是调低模式更改的敏感度,如连续出现多个异色像素再产生反转位;或者使得模式包含实际的长度。但我们还有其他原语可供使用,比如我们可以在合适的位置添加检测点。
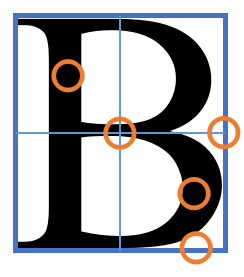
此时,不同字母触发的检测点就容易辨别了。具体的触发判别逻辑见代码 245 行以及之后。
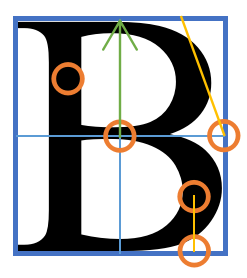
不过哦仅仅添加这些检测点仍然不能完全辨识字母。在正对的情况下,辨识过程是容易的,但是稍微倾斜就会导致一些检测点被触发。我们还需要额外地添加检测线来做进一步的识别。
为了区分 E 和 F, 我们在 (0.8, 1) 到 (0.8, 0.75) 进行线检测,这对应右下角的横。为了区分 A 和 B, 我们在 (1, 0.5) 到 (0.75, 0) 进行线检测,这条线在检查 A 时为白;检查 B 时应该与 B 的上半弧相交而成黑。同时,为了区分 B 和 D, 我们也在 (0.5, 0.5) 向 -y 方向检查距离黑色像素的距离,较短的为 B, 否则为 D.
测试
上机飞行,正确率在 80% 左右,样图如下:

即使图像是倾斜的,也可以稳定触发:

识别失败的主要原因是模式误触发,如此处 A 的模式被误触发:
颜色视觉延伸
人眼的颜色视觉(我们暂时不考虑色盲)比我们想象的要更复杂。我们目前只考虑了在单色模式下的白校正,在之后,我们会继续探索人眼的颜色模式、如何让计算机模拟人眼的视觉,以及是否有必要进行这样的模拟。
Your comments will be submitted to a human moderator and will only be shown publicly after approval. The moderator reserves the full right to not approve any comment without reason. Please be civil.