
We only have so much to play with.
可用内存总大小
在 Cortex-M4 里,可用内存基本上总是确定的——你的片内内存。不过随着硬件的更改,你可能会有更多的可用内存——片外内存。有趣的是 Cortex-M4 确实有片外内存控制器,以及有能力直接执行来自片外内存的代码。
不过我们还是就 STM32F407 的最小默认配置开始,确定可用内存大小。
在之前讨论链接脚本的部分,我们编写了一个最基本的链接脚本让我们的程序可以跑起来,现在我们需要做进一步修改。之前没有使用的 CCMRAM 区域在这里就可以使用了:
/* IN SECTIONS { ... } */
.ccmram :
{
. = ALIGN(4);
*(.ccmram)
*(.ccmram*)
. = ALIGN(4);
PROVIDE(user_start = .);
} >CCMRAM AT> FLASH
现在我们会得到一个来自链接脚本的变量 user_start 作为我们的用户区域内存起始位置:
extern void *user_start;
CCMRAM 的大小从手册中可以知道是 64KiB. 我们可以直接将这个信息写入成宏。我们也可以在链接脚本中填充 CCMRAM 区域并导出尾部地址,再丢弃填充部分使其无需写入 Flash.
内存分配算法
无论我们采取哪种分配算法,我们都需要保证以下内容:
- 被分配的内存的指针在释放前不可移动
- 被分配的内存在释放前不可再次被分配
- 被分配的内存应该是逻辑线性的
那么我们上一节提出的内存链表就已经满足了上述要求。我们可以继续提出一些有趣的分配算法特征:
- 被分配的内存可能会超过当前可用内存
要满足这个要求,我们需要实现过分配算法 (overcommitting).
过分配是操作系统中常见的手法。过分配的假设是:应用程序可能并不会完全用到所分配的所有内存,而未被利用的内存就可以分配给其他应用程序使用。结合内存分页机制,我们可以实现为每个应用程序分配尽量大的内存空间,并在应用程序需要时调入所需页面,而无需担心内存浪费。
然而 STM32F4 并不支持内存分页,所以过分配就暂且不考虑。
在上一节中,我们讨论了内存的基本算法:内存分配子。我们现在展开这个内容。
内存布局
在 STM32F4 内,无论是 CCMRAM 还是普通的片内 RAM, 它们都是连续的。这意味着如果我们能确切知道从哪里开始 RAM 不再被程序使用,之后的内容我们就可以让内存分配系统管理和利用。
从链接脚本内,我们知道 CCMRAM 整片区段都是不被任何程序使用的;当然,如果我们希望使用 SRAM, 我们可以在链接脚本的最后写入 RAM 的区段添加一个符号:
/* IN SECTIONS { ... } */
._user_heap_stack :
{
. = ALIGN(8);
PROVIDE( end = . );
PROVIDE( _end = . );
PROVIDE( __end__ = . );
. = . + _Min_Heap_Size;
. = . + _Min_Stack_Size;
. = ALIGN(8);
PROVIDE( _skylab_memory_start = . ); /* <-- */
} >RAM
这之后,我们就可以开始进行内存的分配工作了。这一块供我们自由使用的内存在下文称为工作内存。
分配与释放算法
在最开始,有一个内存分配子位于工作内存的开头,描述剩下的所有空间。

接下来,应用程序申请内存空间。算法首先检查是否存在一个合适大小的可用空间 (B),如果存在,则将指向该空间的分配子改写成为申请大小,并在该空间之后合适的偏移量创建一个新的分配子 (C) 表示剩下的空间 (D);如果剩下的空间不足以创建一个分配子,那么则不创建新的分配子而直接将整块空间标记为正在使用。

当应用程序释放内存,对应的分配子将被标记为可用。如果有毗邻的可用分配子,那么当前分配子将会被删除,其空间会加入毗邻分配子,形成一块更大的可用空间。
你可能想到了 FreeRTOS 的 heap_4.c. 它们都会将连续可用空间合并以减小内存碎片化。
注意到:分配子和被使用的内存是紧挨着的,它们都在工作内存内。这意味着分配子可能会被意外改写。当然,我们可以分离内存分配表和工作内存,不过目前这个分配方案是可以保证最少内存使用(和浪费)的。在之后,我们会再来处理这个安全问题。
重分配算法
重分配算法思路较为简单:如果当前分配子之后是一个空闲分配子,且其表示的空间足够扩张使用,那么将该空闲分配子向后移动;否则,重新分配内存空间,并将原空间的数据复制到新的内存空间。
内存碎片化
容易想到,即使我们会合并临近空间,内存的碎片化也是不可避免的。考虑这样一个情形:现需要扩大 A 分配子指向的区域。扩张大小可以放在 C 内,但是由于 B 的存在,导致扩张失败。
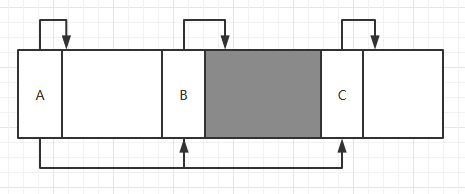
由于没有内存分页,我们没有任何方法能够解决内存碎片化的问题。这一点只能寄希望于开发者能妥善地管理内存。
内存跟踪与回收
内存的回收,主动回收还是很简单的:在内存分配表内查找对应的指针,如果找到了就回收该内存块;没有找到就什么都不做,或者向内核报告错误(释放一个未分配的内存空间)。
如果你是那种非常聪明的同志,你可能会意识到:我们分配的内存块不是紧挨着描述头么?为什么不干脆直接向前挪一下,检查这是否是一个有效的内存块,再释放不就结束了?
这样做的一个危险是你并不知道传入的指针是否来自系统。尽管我们可以通过添加特殊的标记来指示一个内存块头,但是这并不会妨碍用户构造这样的标记出来。尽管严格意义上来说,因为我们设计的是一个用于无人飞行器的嵌入式操作系统而且理论上这玩意也不联网,所以这个问题虽然是个安全问题但也无伤大雅。不过有些时候我们可能会编写出错误的程序而正好出现上述情况,这个时候我们就必须要求内核有能力捕获这个错误。
内存的跟踪则有些有趣。一般而言,当我们谈及内存的跟踪的时候,我们希望知道内存块的具体使用状态,以便之后我们进行垃圾回收等操作。目前而言我们暂时不对 C 语言编写的内容实现垃圾回收。我们可能会在之后引入其他「受管理的」编程语言,比如 Lua 或者 JavaScript, 再进行相应的管理机制。
内存保护
在上一节我们提到了内存保护机制。STM32F4 的内存保护并不像 X86 架构那样复杂强大,其只能分配 8 个区域并给出非常粗粒度的保护。目前而言我们暂且不启用内存保护机制。但这个保护机制仍然是有必要讨论一下的。
内存保护的主要目标是避免用户程序有意或无意写入内核所使用的内存空间,以及避免用户程序之间访问内存。这是为了防止敏感信息泄露或者程序意外地影响系统或其他程序的运行。
Cortex-M 并没有像 x86 那样的复杂的特权级管理和与之相匹配的内存管理体系。所有程序要么运行在特权级,要么运行在非特权级。目前,我们设计的大多数程序都运行在特权级内(内核和驱动),用户程序也不例外。我们在之后的改进中会进一步降低程序的权限,并将内存保护应用到内核。
Cortex-M 支持的内存保护行为包括特权级访问控制和内存属性定义。特权级访问控制是显然的;内存属性则比较有趣。在 Cortex-M 架构中,内存分为普通内存 (Normal Memory) 、设备内存 (Device Memory) 和强制有序内存 (Strongly Ordered Memory). 这个属性用于控制乱序执行行为,即是否允许 CPU 对指令进行重排以提高性能。设备内存和强制有序内存都是在访问时不允许重排的,同时,强制有序内存会等待访问完成后方可继续进行操作——这个特性很适合存储信号量等需要关键时序的内容。我们后面将会应用这个特性。
Your comments will be submitted to a human moderator and will only be shown publicly after approval. The moderator reserves the full right to not approve any comment without reason. Please be civil.