
因为觉得再单独写一个 LaTeX 模板实在是太痛苦了,Word 又不愿意用,那就用博客来写一下好了。反正 Web 化的浪潮拍过来也是很正常的不是么。 ¯\_(ツ)_/¯
数组 Array
数组是最简单的数据结构。可以把数组理解成内存中的连续的一片空间。
在 C 语言中,数组的大小和其长度及类型有关。我们也已经在之前的学习中了解了 C 语言中数组的声明方式,如下:
type name[size] = { initializers, ... };
要获取数组内的某一个元素,也很简单:
type arr[size] = ...;
int index = ...;
arr[index]; // <---
但是我们其实也可以用这个方法来进行数组访问,而且编译器并不会给出错误或者警告:
// ... in main()
int arr[5] = { 0, 1, 2, 3, 4 };
printf("%d\n", 3[a]); // <---
// ...
这提示了我们数组的实质是一个语法糖。所谓语法糖,可以理解为某种常用功能的简写形式。这个写法其实是这个表达方法的简写:
arr[3] == *(arr + 3); // <== true
3[arr] == *(3 + arr); // <== true
但是这并不代表数组名是一个指针。数组名当在上述代码中使用时,其行为和 &arr[0] 是一致的,但是在 sizeof 操作符中,数组名产生的结果是整个数组的大小,而 &arr[0] 的结果是指针本身的大小。
变长数组
数组是定长的,但有时我们希望数组的大小可以随程序的运行而动态扩容。这时候我们可以采取这些方案。
一种是使用 C99 标准引入的变长数组,即变量可以作为数组的大小,如下程序所示:
#include <stdio.h>
void action(int size) {
int arr[size]; // <---
for (int i = 0; i < size; i++) {
arr[i] = i % 5;
}
for (int i = 0; i < size; i++) {
printf("%d ", arr[i]);
}
}
int main() {
action(9); // <== 0 1 2 3 4 0 1 2 3 4
return 0;
}
但是这种方法局限于函数内部使用,对于全局变量而言,使用这个方法是不允许的;即使允许也无法达到我们所期望的效果(动态扩容)。或许我们可以规避使用动态变量,但是我们也必须清楚:在 C 语言中不能返回保存在栈上的变量。即在上面一段代码的 action 函数中,不能将 arr 返回作为函数值。
这里需要提到调用栈(不要慌,下面会具体地学习栈的性质),我们知道当调用一个函数时,系统必须知道当函数返回时应该返回到哪里继续执行,这个返回信息记录在调用栈内。函数声明的局部变量也被保存在栈内。当一个函数返回时,系统会自动清理该函数产生的局部变量并返回到调用函数中。
但是为什么这段代码可以运行而且没有问题呢?
#include <stdio.h>
int answer() {
int answer = 41;
++answer;
return answer;
}
int main() {
printf("The answer to everything is %d\n", answer());
return 0;
}
因为事实上,对于数字(整数、浮点数和指针)返回值,C 语言会将返回值复制到 CPU 的 EAX 寄存器中供接下来的使用,所以即使数字返回值也来自一个局部变量,也不用担心因为变量被清理而丢失数据。
但是对于复杂的结构(数组、结构体和联合体)的返回值,C 语言会先取该结构的地址,复制到 EAX 中,再在之后的代码中自动解引用。由于此时这个结构已经被清理,解引用时就只能读到垃圾信息。
那么我们如何正确地返回一个复杂的结构呢?答案是将这个结构申请在堆空间内,再返回指向这个结构的指针,如下程序所示:
// ...
int* action(int size) {
int* arr = malloc(sizeof(int) * size);
for(int i = 0; i < size; i++) {
arr[i] = i % 5;
}
return arr;
}
// ...
malloc 用于向系统申请内存,free 用于向系统归还内存,这两个函数均声明与 stdlib.h 中。注意到申请有可能会因为可用内存不足失败,当申请失败时,malloc 返回 NULL. 在使用之前需要先检查指针是否为 NULL.
在堆空间内的变量不会因函数返回被自动清理,需要程序员手动清理或者程序退出时由操作系统清理。
那么怎么实现可以动态扩容的数组呢?我们可以尝试使用 realloc 函数,如下程序所示:
#include <stdio.h>
#include <stdlib.h>
int *arr;
int currentSize = 10;
int currentPos = 0;
void addNext5Numbers() {
for(int i = 0; i < 5; i++) {
if (currentPos + i == currentSize) {
arr = realloc(arr, ++currentSize * sizeof(int));
}
arr[currentPos + i] = (currentPos + i) % 5;
}
currentPos += 5;
}
int main() {
arr = malloc(sizeof(int) * currentSize);
for(int i = 0; i < 10; i++) {
addNext5Numbers();
}
for(int i = 0; i < currentSize; i++) {
printf("%d ", arr[i]);
}
free(arr);
return 0;
}
realloc 函数会帮助我们重新分配内存大小,从而实现动态扩容。当然,重新分配大小时可能会失败,也并不保证重分配的内存地址不变,所以我们需要接收可能是新的内存地址。至于旧的地址,realloc 函数会自动帮我们复制内容并清理旧地址。
我们同样需要注意到,realloc 函数是一个开销十分大的工作(事实上所有内存申请操作的开销都十分大,在后面的内存池设计中可见一斑),所以尽管我们可以通过上述代码进行动态扩容,我们需要在实际生产中避免反复零碎地申请内存,而是尽量一次申请足够的内存并在内部进行更高效和更特化的管理。
队列 Queue
单向队列 Queue
单向队列的思路和实际生活中的队列一致——队伍有头有尾,元素从队尾插入、从队头弹出。我们可以通过数组作为队列元素的容器,如下:
struct queue {
size_t size; // 大小
size_t tailPos; // 队尾部位置
type *_arr; // 数组容器
};
之所以不记录队头是因为我们默认队头就是首元素。当我们插入一个元素时,直接向队尾赋值并移动队尾即可;弹出一个元素时,先将首元素复制一份,再逐个将后面的元素向前移动,并将队尾也向前移动即可,如下:
struct queue *queue_new(size_t size) {
struct queue *queue = malloc(sizeof(struct queue));
queue->size = size;
queue->tailPos = 0;
queue->_arr = malloc(sizeof(type) * size);
return queue;
}
void queue_delete(struct queue *queue) {
free(queue->_arr);
free(queue);
}
int queue_push(struct queue *queue, type element) {
queue->_arr[tailPos] = element;
++queue->tailPos;
}
type queue_pop(struct queue *queue) {
type t = queue->_arr[0];
memmove(queue->_arr, queue->_arr + 1, sizeof(type) * (queue->size - 1));
return t;
}
我们注意到这里的 type 在 queue_pop 中返回了。这意味着我们现在这个实现是不能处理复杂的数据类型的。同时我们也可以考虑到,如果这个队列很大,那么移动元素需要的时间就会很长。我们需要尽量减少操作的开销。
那么,假如我们不去移动元素,而是去移动队头的位置,就可以等效成队内元素也一起移动了。当然我们不能一直往后移动(因为这样又要重新分配内存,还会浪费前面分配的空间),所以我们可以让队头或者队尾在数组尾部回卷到数组头部,形成一个环形队列,如下:
struct queue {
size_t size;
size_t head;
size_t tail;
type *_arr;
};
这样我们就可以单纯地通过移动队头和队尾来实现队列了,同时我们还可以返回 type 的指针而不需要担心其为复杂类型,如下:
void queue_push(struct queue *queue, type *element) {
memcpy(queue->_arr + tail, element, sizeof(type));
if (++queue->tail == size) {
queue->tail = 0;
}
}
type *queue_pop(struct queue *queue) {
type *t = queue->_arr + head;
if (++queue->head == size) {
queue->head = 0;
}
return t;
}
当然,我们也可以看到这个代码仍然有不足之处——它不检测队列中是否有元素就会进行弹出,也不检查队列是否已满就会进行写入。至于这个问题:
即得易见平凡,仿照上例显然。 留作习题答案略,读者自证不难。
《西江月·证明》节选(上阕)
双向队列 Deque
双向队列更有趣一些,它在队头和队尾均支持插入和弹出。我们也可以通过简单地更改一个环形队列使之成为环形双向队列。
栈(zhan4)Stack
栈是比较特殊的结构。它只允许在一头进行入栈和出栈操作,先入栈的元素后出栈。我们依然是使用数组来作为栈元素的容器,如下:
struct stack {
size_t size;
size_t sp;
type *_arr;
};
然后实现一下栈的各种操作:
struct stack *stack_new(size_t size) {
struct stack *stack = malloc(sizeof(struct stack));
stack->_arr = malloc(sizeof(type) * size);
stack->size = size;
stack->sp = 0;
}
void stack_delete(struct stack *stack) {
free(stack->_arr);
free(stack);
}
void stack_push(struct stack *stack, type* val) {
memcpy(stack->_arr + sp, val, sizeof(type));
++stack->sp;
}
type* stack_pop(struct stack *stack) {
return stack->_arr + (stack->sp--);
}
为了简洁性依然省略了许多该有的安全检查,只能希望调用者少犯错误。比如我们依然没有检查栈是不是空的就执行了弹出;也没有检查栈是不是已满就执行了压入。这些问题的解决方法留作习题,读者自写不难。
对于安全检查,在生产环境中一般有两种模式:一个是事无巨细地检查;另一个是根本不做检查。前者适用于需要长期运行的应用程序或者一旦崩溃就会产生极端不良影响的程序,比如服务、大型驱动、游戏等;后者适用于一次性代码和对性能与空间都有极致要求的程序,比如竞赛、敢死型嵌入式等。
我们发现在上述代码中,我们都没有对已经离开容器的数据进行任何操作,只是单纯地移动了指针而已。而且我们也可以知道当执行离开容器操作时,返回的数据随时可能被之后进入容器的元素覆盖从而丢失,程序必须立刻将返回元素复制到其他位置上才能保证数据完整。这也是为什么有些 API 会明确提示必须立刻复制返回值的原因。
调用栈 Call stack
谈到了栈就不得不谈一下调用栈 (Call stack). 调用栈是 C 语言用于管理函数调用的一部分特殊内存。每一个程序在启动时会由操作系统分配属于该程序栈空间,这个空间就被用作调用栈。
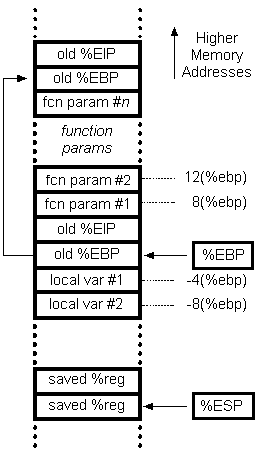
和我们编写的栈不同,调用栈的增长方向是从内存高地址向内存低地址。这么做的原因是为了避免栈溢出时影响到其他应用程序。
虽然这个栈的名字叫做调用栈,但是这里面也不仅仅存储调用信息。在 C 语言中,这个空间还用于存储传入函数的实参 (图中 fcn param)、调用函数时的 CPU 状态 (图中 saved %reg) 和函数使用的局部变量 (图中 local var). 这也解释了为什么如果你尝试声明一个非常大的数组时程序会崩溃:
// ... in main()
int giant_array[2147483648]; // <---
// ...
接下来我们来看一些更复杂的、在生产中也会实际使用的数据结构。之后的示例代码将会添加必要的安全检查以便参考。
位图 Bitmap
稀疏位可以看作一个十分特殊的数组。我们知道 x86 机上 C 语言的内存最小操作精度是字节,但有时我需要存储和使用以位为单位的信息,每一个位都使用一个字节表示就太浪费了。这时我们可以尝试使用位图。
虽然叫「位图」,但这并不是数据结构中的「图」。这纯粹是因为 .bmp 文件格式闹的。
我们仍然使用数组作为数据容器。但是不同的是,我们这回使用 uint8_t 作为类型。这个类型包含在 stdint.h 中,提供平台无关的给定大小的整数。uint8_t 即无符号的 8 位整数。
struct bitmap {
size_t size;
uint8_t *_arr;
};
十分简单,其创建和销毁也是平凡的:
struct bitmap *bitmap_new(size_t size) {
struct bitmap *bitmap = malloc(sizeof(struct bitmap));
if (bitmap == NULL) return NULL;
bitmap->_arr = malloc((size + 7) / 8);
if (bitmap->_arr == NULL) {
free(bitmap);
return NULL;
}
return bitmap;
}
void bitmap_delete(struct bitmap *bitmap) {
if (bitmap == NULL) return;
free(bitmap->_arr);
free(bitmap);
}
但是其访问并不是直白的——我们现在的操作精度是位而不是字节,所以我们必然需要用到一些位操作,如下(注意 & 是 &, 由于博客的限制在代码中我没法打出单独的 &):
void bitmap_set(struct bitmap *bitmap, size_t bit) {
if (bitmap == NULL || bit >= bitmap->size) return;
bitmap->_arr[bit / 8] |= (1 << (bit % 8));
}
void bitmap_clear(struct bitmap *bitmap, size_t bit) {
if (bitmap == NULL || bit >= bitmap->size) return;
bitmap->_arr[bit / 8] &= ~(1 << (bit % 8));
}
bool bitmap_is_set(struct bitmap *bitmap, size_t bit) {
if (bitmap == NULL || bit >= bitmap->size) return false;
return bitmap->_arr[bit / 8] & (1 << (bit % 8));
}
bool bitmap_is_clear(struct bitmap *bitmap, size_t bit) {
return !bitmap_is_set(bitmap, bit);
}
bool bitmap_consecutive_set(struct bitmap *bitmap, size_t bit, size_t count) {
bool flag = true;
for (size_t i = 0; i < count; i++) {
flag &= bitmap_is_set(bitmap, bit + i);
}
return flag;
}
bool bitmap_consecutive_clear(struct bitmap *bitmap, size_t bit, size_t count) {
bool flag = true;
for (size_t i = 0; i < count; i++) {
flag &= bitmap_is_clear(bitmap, bit + i);
}
return flag;
}
如果上述代码看起来并不简单的话,带入值算一下就明白了。毕竟:
反之亦然同理,推论自然成立,略去过程 Q.E.D.,由上可知证毕。
《西江月·证明》节选(下阕)
内存池 Memory Pool
我们在之前反复地使用了 malloc 和 free 操作。这些操作是十分消耗系统资源的。如果我们预料到自己的程序需要反复、大量地申请和释放内存,使用内存池是一个常见的性能提升方法。我们也可以通过此方法学习操作系统是怎样管理内存的。
在这里我们(出于简单)实现定长内存管理模式,即每次都分配同样大小或者这个大小的整数倍的空间。
const int chunkSize = 8; // 每个内存单元为 8 字节
struct mm_pool {
size_t size; // 总大小
void *_data; // 内存空间
struct bitmap *map; // 使用记录
size_t *map_len; // 使用记录
};
struct mm_pool *mm_pool_new(size_t size) {
struct mm_pool* pool = malloc(sizeof(struct mm_pool));
if (pool == NULL) return NULL;
pool->_data = malloc(size);
if (pool->_data == NULL) {
free(pool);
return NULL;
}
pool->map = bitmap_new((size + (chunkSize - 1)) / chunkSize);
if (pool->map == NULL) {
free(pool->_data);
free(pool);
return NULL;
}
pool->map_len = malloc(sizeof(size_t) * (size + chunkSize - 1) / chunkSize);
if (pool->map_len == NULL) {
bitmap_delete(pool->map);
free(pool->_data);
free(pool);
return NULL;
}
return pool;
}
void mm_pool_delete(struct mm_pool* pool) {
if (pool == NULL) return;
bitmap_delete(pool->map);
free(pool->_data);
free(pool);
}
void *mm_pool_alloc(struct mm_pool* pool, size_t size) {
if (size == 0 || pool == NULL) return NULL;
size_t consecutiveChunks = (size + chunkSize - 1) / chunkSize;
for (int i = 0; i < pool->map->size; i++) {
if (bitmap_consecutive_clear(pool->map, i, consecutiveChunks) {
pool->map_len[i] = consecutiveChunks;
for (size_t j = 0; j < consecutiveChunks; j++) {
bitmap_set(pool->map, i + j);
}
return pool->_data + i;
}
}
return NULL;
}
void mm_pool_free(struct mm_pool* pool, void *ptr) {
if (pool == NULL || ptr == NULL) return;
size_t offset = (size_t) ptr - pool->_data;
if (pool->map_len[offset] < 1) return;
for (size_t i = 0; i < pool->map_len[offset]; i++) {
bitmap_clear(pool->map, offset + i);
}
pool->map_len[offset] = 0;
}
我们关心到 mm_pool_alloc 和 mm_pool_free 两个函数,这两个函数和 malloc 和 free 有同样的作用。
内存泄漏 Memory leak
之前提到「申请的内存需要向系统归还」。如果我硬是不还,会发生什么?
这时候就会发生传说中的内存泄漏。内存泄漏属于一种隐形问题,在程序的运行中甚至不会出现任何表征,但是一旦出现问题基本上都是非常难以调试的致命伤——毕竟这种问题有时需要连续几个月的运行和操作才会被触发。
那么我们怎么来调试内存泄漏问题呢?在开发过程中,我们可以使用 Valgrind 进行内存跟踪,从而发现问题。当然现代 IDE 也会进行一定提示。
缓冲区溢出和缓冲区超读 Buffer Overflow | Buffer Overread
我们观察这样一个程序:
// ...
char buf[10];
gets(buf);
// ...
看起来很「正常」,无非是读入输入而已。
但是如果我们尝试输入超过 10 个字符,这个程序并不会出现任何错误。当然有时候你会发现你的 IDE 卡死了程序,并指出在该处内存访问越界;或者抛出一个 SIGSEGV 然后应用程序已停止运行。这时发生的事情就是缓冲区溢出——你写入的数据比你申请的内存占用更大空间。
这还会导致一些安全隐患。有一个典型的例子/段子叫 dir 溢出,即在 NT 5 (XP) 以及之前你可以通过 dir 命令对系统进行攻击,比如:dir aux.AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA蛱矣 可以在 Win2K 上锁定计算机(和按下 Win+L 的效果一样),原理即利用了缓冲区溢出,将调用栈栈上的返回地址改写为 User32!LockWorkStation 的地址,那么函数在返回时就会进入对应函数,进而锁定计算机。
我们再来观察这样一个程序:
// ...
buf[255];
fgets(buf, 255, stdin);
for(int i = 0; i < 255; i++)
putchar(buf[i]);
// ...
这次我们使用了 fgets 检查输入的长度,所以不会发生缓冲区溢出。之后的读取也没有超过 buf 的长度,所以看起来挺正常。
但是如果我们的输入实际上小于 255 个字符,那么在读出我们的输入之后,程序又会读到什么呢?答案是什么都有可能——之前输入的内容、其他程序运行过后留下的内容或者内存中的垃圾信息。这时发生的事情就是缓冲区超读——你读取的数据比已经存在的数据要多。
这同样也会产生安全隐患,著名的心脏出血 (Heartbleed) 漏洞就是一个典型的内存超读的例子。具体的玩法,Randall 已经给出了十分形象的解释:

Your comments will be submitted to a human moderator and will only be shown publicly after approval. The moderator reserves the full right to not approve any comment without reason. Please be civil.